


May 18
K-Means Clustering
Click on the images to see them clearly

#!/usr/bin/env python
coding: utf-8
In[1]:
k-means clustering
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from matplotlib import pyplot
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
get_ipython().run_line_magic(‘matplotlib’, ‘inline’)
import pandas as pd
import numpy as np
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
In[2]:
import warnings
warnings.filterwarnings(‘ignore’)
In[3]:
the combined data
data_folder = ‘./nhanes_input_data/’
import the CSV as a pandas dataframe
df = pd.read_csv( data_folder + ‘0_dietaryIntakeDataForClassificationAndAnalysisData.csv’)
df.shape
In[4]:
df.head(5)
In[5]:
parameters to be used for KMeans clustring: centres
X and/or kdf will have only features we want to create cluster around
kdf = df[
[
'RIDAGEYR_Age_in_years_at_screening'
,'URDACT_Albumin_creatinine_ratio_mg_g'
]
]
X = kdf
X[:5]
In[6]:
ref: internet (not my code, using as a library)
def clean_dataset(df):
assert isinstance(df, pd.DataFrame), "df needs to be a pd.DataFrame"
df.dropna(inplace=True)
indices_to_keep = ~df.isin([np.nan, np.inf, -np.inf]).any(1)
return df[indices_to_keep].astype(np.float64)
In[7]:
X has the features to cluster around (centres: Age, ACR). df has the complete data
after clustering is done using features in X, we find positions (index) for each data
in a cluster then we use those index positions to cluster the data from df
X.shape, df.shape
In[8]:
X = clean_dataset(X)
In[9]:
define the model
model = KMeans(n_clusters = 10) #,random_state=0, n_init="auto"
fit the model
model.fit(X)
#model.labels_
In[10]:
Create csv files with the cluster daya
One csv for one Cluster
In[11]:
howManyClusters = 10
for clusterId in range (howManyClusters):
ind_list = np.where(model.labels_ == clusterId )[0]
cluster = df.iloc[ind_list]
cluster.to_csv(‘./nhanes_output_data/classifiedGroups/kmeanscluster/cluster-‘
+ str(clusterId) + ‘.csv’);
In[12]:
model.cluster_centers_
In[13]:
Scatter plot to see each cluster points visually
std_data = StandardScaler().fit_transform(X)
plt.scatter(std_data[:,0], std_data[:,1], c = model.labels_, cmap = "rainbow")
plt.title("K-means Clustering of Diet and ACR data")
plt.show()
# References:
# print("Shape of cluster:", model.cluster_centers_.shape)
# https://stackoverflow.com/questions/50297142/get-cluster-points-after-kmeans-in-a-list-format
#
# https://machinelearningmastery.com/clustering-algorithms-with-python/
# https://stackoverflow.com/questions/50297142/get-cluster-points-after-kmeans-in-a-list-format
# https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
# https://datascience.stackexchange.com/questions/48693/perform-k-means-clustering-over-multiple-columns
# https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
#
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
… [10, 2], [10, 4], [10, 0]])
>>> kmeans = KMeans(n_clusters=2, random_state=0, n_init="auto").fit(X)
>>> kmeans.labels_
array([1, 1, 1, 0, 0, 0], dtype=int32)
>>> kmeans.predict([[0, 0], [12, 3]])
array([1, 0], dtype=int32)
>>> kmeans.cluster_centers_
array([[10., 2.],
[ 1., 2.]])
In[ ]:

May 17
C# Application using VS Code
You need C# Dev Kit. .Net Install Tools (.Net Runtime Install Tools), .Net SDK, and extensions that these extensions also depend on.
Then >.net option will give you the project create, open, build or similar features – Check Image below)
Having Visual Studio is the best option (and in Windows Environment under VM (Parallels or Oracle Virtual Box, VMWARE, Similar) or not ).
Creating .Net C# project in VS Code

Hope this helps.
May 13
Oracle: Error management and exception handling in PL/SQL
Raise Error in Oracle
RAISE VALUE_ERROR;
Raise Application Error in Oracle

Create custom exception and raise it.
Handle Exception


You could also insert into error log table and RAISE
Reference:
https://blogs.oracle.com/connect/post/error-management
May 12
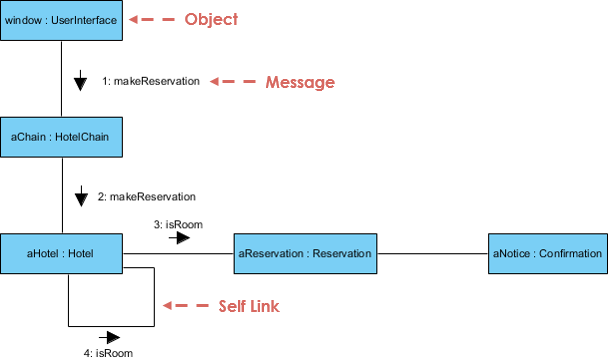
UML Collaboration Diagram
"Collaboration diagrams (known as Communication Diagram in UML 2.x) are used to show how objects interact to perform the behavior of a particular use case, or a part of a use case. Along with sequence diagrams, collaboration are used by designers to define and clarify the roles of the objects that perform a particular flow of events of a use case. They are the primary source of information used to determining class responsibilities and interfaces."
Ref: Check Below

May 12
Oracle PL/SQL: If-Then-Else, For Loop, While Loop
How it works: if, elsif, else (then) (Click on the images to see them clearly)

Ref: https://docs.oracle.com/cd/B13789_01/appdev.101/b10807/13_elems024.htm
Example:

Ref: https://docs.oracle.com/cd/B13789_01/appdev.101/b10807/13_elems024.htm
Oracle: CASE, WHEN, THEN
Simple:
Searched:
”
Else:
Reverse For Loop

Ref: For Loop Examples in Oracle
https://docs.oracle.com/cd/E11882_01/appdev.112/e25519/controlstatements.htm#BABEFFDC
Oracle While Loop
While loop example from the referenced url
DECLARE
done BOOLEAN := FALSE;
BEGIN
WHILE done LOOP
DBMS_OUTPUT.PUT_LINE (‘This line does not print.’);
done := TRUE; — This assignment is not made.
END LOOP;
WHILE NOT done LOOP
DBMS_OUTPUT.PUT_LINE (‘Hello, world!’);
done := TRUE;
END LOOP;
END;
/
May 12
Oracle Sub Types for Data Types: Exception Block
An unconstrained subtype has the same set of values as its base type, so it is only another name for the base type.
Syntax:
SUBTYPE subtype_name IS base_type
Example:
SUBTYPE "DOUBLE PRECISION" IS FLOAT
SUBTYPE Balance IS NUMBER;
Constrained SubType
SUBTYPE Balance IS NUMBER(8,2);
Oracle Exception Block Example:
Ref: https://docs.oracle.com/cd/B13789_01/appdev.101/b10807/07_errs.htm
May 12
Misc. Oracle: Data Types: Why a Data Type.

Ref: https://docs.oracle.com/cd/B13789_01/appdev.101/b10807/02_funds.htm

https://stackoverflow.com/questions/7425153/reason-why-oracle-is-case-sensitive
Oracle Data Types and Allowed Sizes:

https://docs.oracle.com/cd/E11882_01/appdev.112/e25519/datatypes.htm#LNPLS99943
Oracle SIMPLE_FLOAT vs SIMPLE_DOUBLE

Ref: https://docs.oracle.com/cd/B28359_01/appdev.111/b28370/datatypes.htm#CJAEAEJG
PLS_Integer vs Number
"The PLS_INTEGER data type has these advantages over the NUMBER data type and NUMBER subtypes:
PLS_INTEGERvalues require less storage.PLS_INTEGERoperations use hardware arithmetic, so they are faster thanNUMBERoperations,
"
Ref: https://docs.oracle.com/cd/E11882_01/appdev.112/e25519/datatypes.htm#LNPLS319
Hardly anything is by me. All are from external sources. Credit belongs to them.

{kind=link}